

Sundance Basics
The Finite Element Method
Sundance solves PDEs using the finite-element method: a general, powerful, and quite elegant method for turning a PDE into a discrete system of algebraic equations. To use Sundance, you will need to understand the fundamentals of the finite-element method. This is not the place to teach you the finite-element method -- many good books on the subject are available -- but it is worth pointing out some salient features of the finite-element method and their impact on how you will use Sundance.- A finite-element model of a PDE is based on a weak form of the PDE. You will describe a PDE in Sundance code using a high-level symbolic notation for writing weak forms. There can be more than one way to derive a weak form for a given PDE.
- The geometric domain for your problem will decomposed into a discrete mesh of cells. Meshing a continuous geometric figure represented by an equation or CAD drawing is a difficult problem in both theory and practice. Sundance has some simple mesh generation capability built in; however, for all but the simplest toy problems you will instead want to use a third-party mesher and import that mesh into Sundance.
- A finite-element model approximates a PDE by a discrete system of algebraic equations: linear algebraic equations for a linear PDE, nonlinear equations for a nonlinear PDE. This process of going from a PDE to an system of algebraic equations is called discretization. There are many factors that influence the final discrete form of the equation: choice of weak form, method of imposing BCs, basis functions for the unknowns in the problem, and more.
-
Designing algorithms, or solvers, for solving large system of linear equations is another difficult area of computational mathematics. There is definitely not a one-size-fits-all solver for
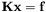 . The optimal solver for a given problem can depend critically on the structure of the stiffness matrix
. The optimal solver for a given problem can depend critically on the structure of the stiffness matrix 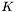 . Sundance lets you choose a solver to suit the structure of your problem, and provides an interface for plugging in high-performance linear algebra software.
. Sundance lets you choose a solver to suit the structure of your problem, and provides an interface for plugging in high-performance linear algebra software. - Solution of a nonlinear problem can be reduced to solving a sequence of linear problems. There are many choices of linearization method and iteration method for a nonlinear problem, each of which will result in a different sequence of linear problems.
- Solution of a time-dependent problem can be reduced to solving a sequence of linear (or possibly nonlinear) problems, by timestepping or marching. Again, there are many possible marching algorithms.
After reading the above list you should have the idea that solving PDEs with the finite-element method is a very open-ended business, and that in designing a simulation you will be faced with a large number of choices. Sundance is intended to let you make those choices by selecting and combining high-level objects rather than by writing low-level code. Note that while Sundance makes it easy for you to try many options for formulation, discretization, and solution, it cannot by itself help you make good choices for a given problem -- for that you will have to rely on your understanding of the problem. Unfortunately, Sundance has no way to detect if you use its components to build an unstable or innaccurate discretization, write ill-posed boundary conditions, or choose a solver that is inefficient for your problem.
Declarative Programming
Writing a simulator with Sundance components is somewhat different from writing one with FORTRAN subroutines or even lower-level C++ objects than those used in Sundance. Programming with Sundance components is essentially declarative programming. One defines a suite of objects that specify the mesh, equations, boundary conditions, solver, and so on, and marshals them into an object that can produce the solution to a problem. In many cases, it will not be necessary for you as a simulation developer to write any loops, conditionals, or other procedural constructions. Tasks such as looping over mesh cells or deciding where to apply boundary conditions is done inside certain methods of the top-level LinearProblem and NonlinearProblem objects. The iterators and conditionals required to control that process are deduced from information provided by the components from which you assembled the Problem objects.About the code and the documentation
Sundance is written in the C++ programming language. To write your own Sundance simulation, you will have to write and compile C++. However, you need not be an expert C++ programmer, because you can do most things using Sundance's predefined objects. The trick to writing Sundance code is to understand the behavior of the user-level objects. The main purpose of this document is to show you how to use Sundance's user-level objects to set up and solve PDEs.Typographical conventions in the source code and examples
Class names begin with capital letters, and each word within the name also begins capitalized. For example: MeshSource and DiscreteFunction are classes. Method names and variables begin with lower-case letters, but subsequent words within the name are capitalized. For example: getCells() and numCells() are methods. If you forge on to read the developer's documentation or source code, you will need to know that data member names end with an underscore, for example: myName.Handles and Memory Management
Understanding handle classes and how they are used in Sundance is important for reading and writing Sundance code and browsing the source and class documentation. Handle classes are used in Sundance to simplify user-level polymorphism and provide transparent memory management.Polymorphism is a buzzword meaning the representation of different but related object types (derived classes, or subclasses) through a common interface (the base class). In C++, you can't use a base-class object to represent a derived class; you have to use a pointer to the base class object to represent a pointer to the derived class. That leads to a rather awkward syntax and also requires attention to memory management. To simplify the interface and make memory management automatic, all user-level polymorphism is done with handle classes. A handle class is simply a class that contains a pointer to a base class, along with an interface providing user-callable methods, and a (presumably) intelligent scheme for memory management.
So if you want to work with a family of Sundance objects, for instance the different flavors of symbolic objects, you need only use:
- the methods of the handle class for that family of classes
- the constructors for the derived classes.
For example, Sundance symbolic objects are represented with a handle class called Expr. The different symbolic types derive from a class called ExprBase, but they are never used directly after construction; they are used only through the Expr handle class. The code fragment below shows some Exprs being constructed through subclass constructors and then being used in Expr operations.
Expr x = new CoordExpr(0, "x"); Expr f = x + 3.0*sin(x); Expr dx = new Derivative(0); Expr df = dx*f;
new but never delete.Thanks to handles, when writing Sundance code you can always assume that
- User-level classes have well-defined behavior for copying and assignment.
- User-level classes have well-defined destructors, and take care of their own memory management.
Copying of Sundance objects
Data structures in a PDE simulation can become rather large; for this reason, objects such as meshes, matrices, and degree-of-freedom maps are shallow-copied so that both the original and the copy refer to the same chunk of memory. A reference counted "smart pointer" inside the handle is used to ensure that data is deleted only when necessary. It is important to understand that such a copying scheme leads to side effects: when a copy is modified, the original is modified as well. When all copies point back to a single object, the object is said to have "shallow" copy behavior. So big Sundance objects such as meshes, matrices, and maps are shallow copied.
Expressions are shallow-copied as well. Though not important for conserving memory, shallow copying expression is important for performance because it can help avoid redundant evaluation of complicated expressions. Suppose, for example, that your equation contains 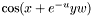 in several places. You can define an intermediate expression
in several places. You can define an intermediate expression
Expr f = cos(x + exp(-u)*y*w);
appears, for instance, Expr g = v*f + f*(dx*v)*(dx*u) + v*sqrt(1.0 + f*f);
 , a value for
, a value for 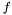 will be computed once and reused throughout the calculation. This is made possible by the shallow copy behavior of expressions: all copies of in the expression for point back to the same object, so upon evaluation its value is available everywhere it appears within .
will be computed once and reused throughout the calculation. This is made possible by the shallow copy behavior of expressions: all copies of in the expression for point back to the same object, so upon evaluation its value is available everywhere it appears within .The shallow copy property of Expr has another important application: it allows after-the-fact modification of expressions buried within larger expressions. In particular, it allows the simulator to update values of Parameter and DiscreteFunction expressions in place during the course of run.
Just to be pedantic
Note: In this document I will often speak of a derived type such as CoordExpr as being a subclass of its handle, in this case Expr. Strictly speaking, this isn't correct; CoordExpr is a subclass of ExprBase, not Expr. However, it does convey the essence of how CoordExpr and Expr are used in writing a simulation; a simulation developer will never see ExprBase at all. Indeed, were Sundance written in Java (as it might have been, had Java provided operator overloading), ExprBase wouldn't even exist, and CoordExpr would derive directly from Expr. The introduction of handles is solely a way of getting clean syntax for polymorphism and operator overloading within C++.Parallel computation
Sundance can both assemble and solve systems in parallel. Parallel Sundance uses the SPMD paradigm, in which the same code is run on all processors. Communication is done using MPI, accessed through object wrappers in the Teuchos utilities package within Trilinos. To use Sundance's parallel capabilities, Trilinos must be built with MPI enabled. See the installation documentation for help in installing parallel Sundance.One of the design goals was to make parallel solves look to the user as much as possible like serial solves. In particular, the symbolic description of an equation set and boundary conditions is completely unchanged from serial to parallel runs. To run a problem in parallel, you simply need to use a parallel solver (such as most of the iterative solvers available in Trilinos) and use a partitioned mesh. A subsequent section contains information on creating Distributed Meshes.
Operations such as norms and definite integrals on discrete functions are done such that the result is collected from all processors.